[ad_1]
This text is a part of Demystifying AI, a sequence of posts that (attempt to) disambiguate the jargon and myths surrounding AI. (In partnership with Paperspace)
In recent times, the transformer fashion has transform one of the vital major highlights of advances in deep finding out and deep neural networks. It’s principally used for complicated programs in herbal language processing. Google is the use of it to strengthen its seek engine effects. OpenAI has used transformers to create its well-known GPT-2 and GPT-3 fashions.
Since its debut in 2017, the transformer structure has developed and branched out into many various variants, increasing past language duties into different spaces. They have got been used for time sequence forecasting. They’re the important thing innovation in the back of AlphaFold, DeepMind’s protein construction prediction fashion. Codex, OpenAI’s supply code–era fashion, is in accordance with transformers. Extra just lately, transformers have discovered their means into pc imaginative and prescient, the place they’re slowly changing convolutional neural networks (CNN) in lots of sophisticated duties.
Researchers are nonetheless exploring techniques to reinforce transformers and use them in new programs. Here’s a temporary explainer about what makes transformers thrilling and the way they paintings.
Processing sequences with neural networks
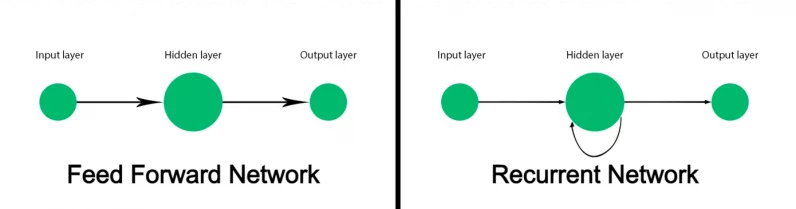
The vintage feed-forward neural community isn’t designed to stay observe of sequential information and maps each and every enter into an output. This works for duties reminiscent of classifying photographs however fails on sequential information reminiscent of textual content. A system finding out fashion that processes textual content should now not simplest compute each and every phrase but in addition take into accounts how phrases are available in sequences and relate to one another. The that means of phrases can trade relying on different phrases that come earlier than and after them within the sentence.
Ahead of transformers, recurrent neural networks (RNN) have been the go-to answer for herbal language processing. When supplied with a series of phrases, an RNN processes the primary phrase and feeds again the end result into the layer that processes the following phrase. This permits it to stay observe of all the sentence as a substitute of processing each and every phrase one after the other.
Recurrent neural nets had disadvantages that restricted their usefulness. First, they have been very gradual. Since they needed to procedure information sequentially, they may now not benefit from parallel computing {hardware} and graphics processing devices (GPU) in coaching and inference. 2d, they may now not care for lengthy sequences of textual content. Because the RNN were given deeper right into a textual content excerpt, the consequences of the primary phrases of the sentence step by step light. This downside, referred to as “vanishing gradients,” used to be problematic when two related phrases have been very a ways aside within the textual content. And 3rd, they simply captured the family members between a phrase and the phrases that got here earlier than it. In truth, the that means of phrases relies on the phrases that come each earlier than and after them.
Lengthy temporary reminiscence (LSTM) networks, the successor to RNNs, have been ready to resolve the vanishing gradients downside to a point and have been ready to care for higher sequences of textual content. However LSTMs have been even slower to coach than RNNs and nonetheless couldn’t take complete benefit of parallel computing. They nonetheless relied at the serial processing of textual content sequences.
Transformers, presented within the 2017 paper “Consideration Is All You Want,” made two key contributions. First, they made it imaginable to procedure complete sequences in parallel, making it imaginable to scale the velocity and capability of sequential deep finding out fashions to remarkable charges. And 2d, they presented “consideration mechanisms” that made it imaginable to trace the family members between phrases throughout very lengthy textual content sequences in each ahead and opposite instructions.
Processing sequences with neural networks
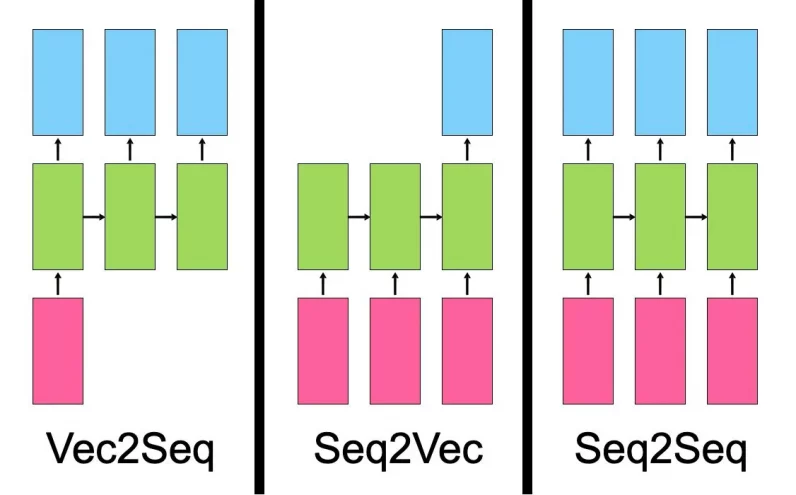
Ahead of we talk about how the transformer fashion works, it’s price discussing the varieties of issues that sequential neural networks resolve.
A “vector to series” fashion takes a unmarried enter, reminiscent of a picture, and produces a series of knowledge, reminiscent of an outline.
A “series to vector” fashion takes a series as enter, reminiscent of a product evaluate or a social media publish, and outputs a unmarried worth, reminiscent of a sentiment rating.
A “series to series” fashion takes a series as enter, reminiscent of an English sentence, and outputs any other series, such because the French translation of the sentence.
Regardless of their variations, all most of these fashions have something in commonplace. They be informed representations. The task of a neural community is to grow to be one form of information into any other. Throughout coaching, the hidden layers of the neural community (the layers that stand between the enter and output) music their parameters in some way that absolute best represents the options of the enter information kind and maps it to the output.
The unique transformer used to be designed as a sequence-to-sequence (seq2seq) fashion for system translation (after all, seq2seq fashions don’t seem to be restricted to translation duties). It’s composed of an encoder module that compresses an enter string from the supply language right into a vector that represents the phrases and their family members to one another. The decoder module transforms the encoded vector right into a string of textual content within the vacation spot language.
Tokens and embeddings
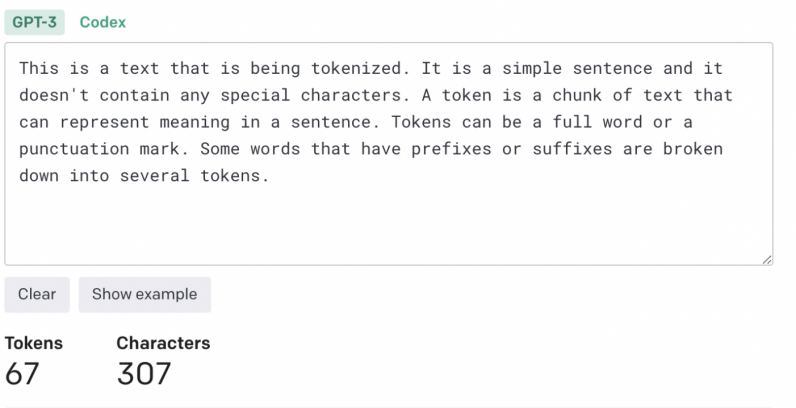

The enter textual content should be processed and reworked right into a unified layout earlier than being fed to the transformer. First, the textual content is going via a “tokenizer,” which breaks it down into chunks of characters that may be processed one after the other. The tokenization set of rules can rely at the software. Generally, each and every phrase and punctuation mark more or less counts as one token. Some suffixes and prefixes rely as separate tokens (e.g., “ize,” “ly,” and “pre”). The tokenizer produces an inventory of numbers that constitute the token IDs of the enter textual content.
The tokens are then transformed into “phrase embeddings.” A phrase embedding is a vector that tries to seize the price of phrases in a multi-dimensional house. For instance, the phrases “cat” and “canine” will have identical values throughout some dimensions as a result of they’re each utilized in sentences which might be about animals and area pets. On the other hand, “cat” is nearer to “lion” than “wolf” throughout another measurement that separates pussycats from canids. In a similar way, “Paris” and “London” could be shut to one another as a result of they’re each towns. On the other hand, “London” is nearer to “England” and “Paris” to “France” on a measurement that separates international locations. Phrase embeddings most often have masses of dimensions.
Phrase embeddings are created by way of embedding fashions, that are skilled one after the other from the transformer. There are a number of pre-trained embedding fashions which might be used for language duties.
Consideration layers
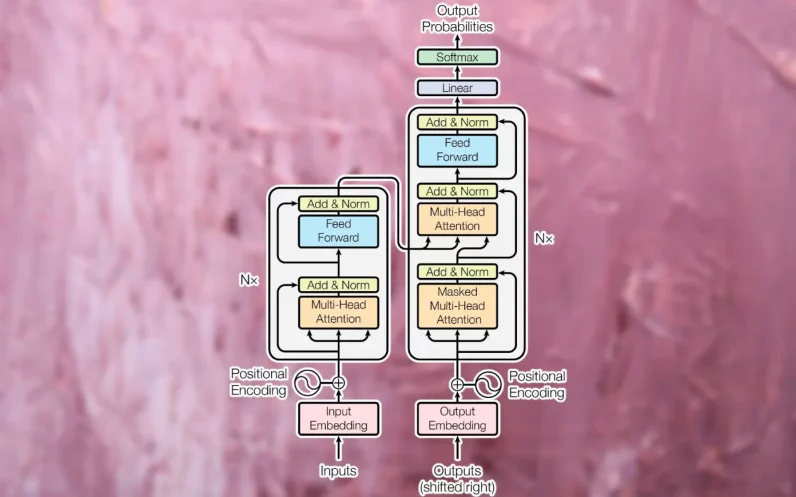
As soon as the sentence is reworked into an inventory of phrase embeddings, it’s fed into the transformer’s encoder module. In contrast to RNN and LSTM fashions, the transformer does now not obtain one enter at a time. It might probably obtain a whole sentence’s price of embedding values and procedure them in parallel. This makes transformers extra compute-efficient than their predecessors and likewise allows them to inspect the context of the textual content in each ahead and backward sequences.
To maintain the sequential nature of the phrases within the sentence, the transformer applies “positional encoding,” which mainly implies that it modifies the values of each and every embedding vector to constitute its location within the textual content.
Subsequent, the enter is handed to the primary encoder block, which processes it via an “consideration layer.” The eye layer tries to seize the family members between the phrases within the sentence. For instance, imagine the sentence “The large black cat crossed the street after it dropped a bottle on its aspect.” Right here, the fashion should affiliate “it” with “cat” and “its” with “bottle.” Accordingly, it must determine different associations reminiscent of “large” and “cat” or “crossed” and “cat.” Another way put, the eye layer receives an inventory of phrase embeddings that constitute the values of person phrases and produces an inventory of vectors that constitute each person phrases and their family members to one another. The eye layer accommodates more than one “consideration heads,” each and every of which is able to seize other types of family members between phrases.
The output of the eye layer is fed to a feed-forward neural community that transforms it right into a vector illustration and sends it to the following consideration layer. Transformers comprise a number of blocks of consideration and feed-forward layers to step by step seize extra sophisticated relationships.
The duty of the decoder module is to translate the encoder’s consideration vector into the output information (e.g., the translated model of the enter textual content). Throughout the learning section, the decoder has get admission to each to the eye vector produced by way of the encoder and the anticipated end result (e.g., the translated string).
The decoder makes use of the similar tokenization, phrase embedding, and a spotlight mechanism to procedure the anticipated end result and create consideration vectors. It then passes this consideration vector and the eye layer within the encoder module, which establishes family members between the enter and output values. Within the translation software, that is the section the place the phrases from the supply and vacation spot languages are mapped to one another. Just like the encoder module, the decoder consideration vector is handed via a feed-forward layer. Its result’s then mapped to an overly huge vector which is the scale of the objective information (on the subject of language translation, it will span throughout tens of hundreds of phrases).
Coaching the transformer
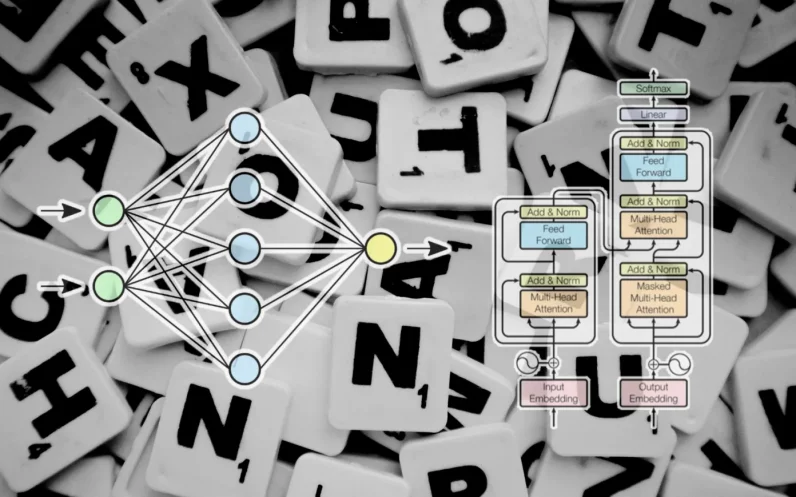
Throughout coaching, the transformer is supplied with an overly huge corpus of paired examples (e.g., English sentences and their corresponding French translations). The encoder module receives and processes the overall enter string. The decoder, then again, receives a masked model of the output string, one phrase at a time, and tries to determine the mappings between the encoded consideration vector and the anticipated end result. The encoder tries to are expecting the following phrase and makes corrections in accordance with the adaptation between its output and the anticipated end result. This comments allows the transformer to switch the parameters of the encoder and decoder and step by step create the precise mappings between the enter and output languages.
The extra coaching information and parameters the transformer has, the extra capability it positive factors to deal with coherence and consistency throughout lengthy sequences of textual content.
Permutations of the transformer
Within the system translation instance that we tested above, the encoder module of the transformer discovered the family members between English phrases and sentences, and the decoder learns the mappings between English and French.
However now not all transformer programs require each the encoder and decoder module. For instance, the GPT circle of relatives of huge language fashions makes use of stacks of decoder modules to generate textual content. BERT, any other variation of the transformer fashion evolved by way of researchers at Google, simplest makes use of encoder modules.
The good thing about a few of these architectures is that they are able to be skilled via self-supervised finding out or unsupervised strategies. BERT, as an example, does a lot of its coaching by way of taking huge corpora of unlabeled textual content, protecting portions of it, and looking to are expecting the lacking portions. It then tunes its parameters in accordance with how a lot its predictions have been as regards to or a ways from the real information. Via often going via this procedure, BERT captures the statistical family members between other phrases in several contexts. After this pretraining section, BERT may also be finetuned for a downstream job reminiscent of query answering, textual content summarization, or sentiment research by way of coaching it on a small selection of categorised examples.
The usage of unsupervised and self-supervised pretraining reduces the guide effort required to annotate coaching information.
Much more may also be mentioned about transformers and the brand new programs they’re unlocking, which is out of the scope of this newsletter. Researchers are nonetheless discovering techniques to squeeze extra out of transformers.
Transformers have additionally created discussions about language figuring out and synthetic basic intelligence. What is apparent is that transformers, like different neural networks, are statistical fashions that seize regularities in information in suave and complex techniques. They don’t “perceive” language in the way in which that people do. However they’re thrilling and helpful however and feature so much to provide.
This text used to be at the beginning written by way of Ben Dickson and revealed by way of Ben Dickson on TechTalks, a e-newsletter that examines developments in era, how they impact the way in which we are living and do trade, and the issues they resolve. However we additionally talk about the evil aspect of era, the darker implications of latest tech, and what we want to glance out for. You’ll learn the unique article right here.
[ad_2]
Fonte da Notícia
:strip_icc()/i.s3.glbimg.com/v1/AUTH_59edd422c0c84a879bd37670ae4f538a/internal_photos/bs/2022/1/l/AsRyC7TmeXfWaCFgFVug/ana-canas.png "Instagram derruba selfie em que Ana Cañas aparece nua em frente ao espelho | Tecnologia")


