AI que get to the bottom of problemas de matemática, traduz 200 idiomas e desenha cangurus – TechCrunch
[ad_1]
A pesquisa no campo de aprendizado de máquina e IA, agora uma tecnologia-chave em praticamente todos os setores e empresas, é volumosa demais para que qualquer um leia tudo. Esta coluna, Perceptron, visa coletar algumas das descobertas e artigos recentes mais relevantes – particularmente, mas não limitado a, inteligência synthetic – e explicar por que eles são importantes.
Neste lote de pesquisas recentes, a Meta abriu o código-fonte de um sistema de linguagem que afirma ser o primeiro capaz de traduzir 200 idiomas diferentes com resultados “de última geração”. Para não ficar para trás, o Google detalhou um modelo de aprendizado de máquina, Minerva, que pode resolver problemas de raciocínio quantitativo, incluindo questões matemáticas e científicas. E a Microsoft lançou um modelo de linguagem, Godel, por gerar conversas “realistas” que seguem as linhas do amplamente divulgado Lamda do Google. E então temos alguns novos geradores de texto para imagem com um toque diferente.
O novo modelo da Meta, NLLB-200, faz parte da iniciativa No Language Left In the back of da empresa para desenvolver recursos de tradução automática para a maioria dos idiomas do mundo. Treinado para entender idiomas como Kamba (falado pelo grupo étnico Bantu) e Lao (o idioma oficial do Laos), bem como mais de 540 idiomas africanos não suportados bem ou em todos os sistemas de tradução anteriores, o NLLB-200 será usado para traduzir idiomas no feed de notícias do Fb e no Instagram, além da ferramenta de tradução de conteúdo da Wikimedia Basis, anunciou recentemente a Meta.
A tradução de IA tem o potencial de escalar muito – e já tem escalado – o número de idiomas que podem ser traduzidos sem conhecimento humano. Mas, como alguns pesquisadores notaram, erros que abrangem terminologia incorreta, omissões e erros de tradução podem surgir em traduções geradas por IA porque os sistemas são treinados em grande parte com dados da Web – nem todos de alta qualidade. Por exemplo, o Google Tradutor já pressupôs que médicos eram homens enquanto enfermeiras eram mulheres, enquanto o tradutor do Bing traduziu frases como “a mesa é macia” como o feminino “die Tabelle” em alemão (que se refere a uma tabela de números).
Para o NLLB-200, a Meta disse que “reformulou completamente” seu pipeline de limpeza de dados com “principais etapas de filtragem” e listas de filtragem de toxicidade para o conjunto completo de 200 idiomas. Resta ver como isso funciona na prática, mas – como os pesquisadores do Meta por trás do NLLB-200 reconhecem em um artigo acadêmico descrevendo seus métodos – nenhum sistema está completamente livre de vieses.
Gõdel, da mesma forma, é um modelo de linguagem treinado em uma vasta quantidade de texto da internet. No entanto, ao contrário do NLLB-200, Gõdel foi projetado para lidar com diálogos “abertos” – conversas sobre uma variedade de tópicos diferentes.
Créditos da imagem: Microsoft
Gõdel pode responder a uma pergunta sobre um restaurante ou conversar sobre um assunto específico, como a história de um bairro ou um jogo esportivo recente. De maneira útil, e como o Lamda do Google, o sistema pode utilizar conteúdo de toda a internet que não fazia parte do conjunto de dados de treinamento, incluindo avaliações de restaurantes, artigos da Wikipedia e outros conteúdos em websites públicos.
Mas Gõdel encontra as mesmas armadilhas que o NLLB-200. Em um artigo, a equipe responsável por criá-lo observa que “pode gerar respostas prejudiciais” devido às “formas de viés social e outras toxicidades” nos dados usados para treiná-lo. Eliminar, ou mesmo mitigar, esses vieses continua sendo um desafio não resolvido no campo da IA – um desafio que pode nunca ser completamente resolvido.
O modelo Minerva do Google é menos potencialmente problemático. Como a equipe por trás dele descreve em uma postagem no weblog, o sistema aprendeu com um conjunto de dados de artigos científicos de 118 GB e páginas da internet contendo expressões matemáticas para resolver problemas de raciocínio quantitativo sem usar ferramentas externas como uma calculadora. O Minerva pode gerar soluções que incluem cálculos numéricos e “manipulação simbólica”, alcançando desempenho líder em benchmarks STEM populares.
O Minerva não é o primeiro modelo desenvolvido para resolver esses tipos de problemas. Para citar alguns, o DeepMind da Alphabet demonstrou vários algoritmos que podem ajudar os matemáticos em tarefas complexas e abstratas, e o OpenAI tem experimentou com um sistema treinado para resolver problemas de matemática em nível de escola primária. Mas o Minerva incorpora técnicas recentes para resolver melhor questões matemáticas, diz a equipe, incluindo uma abordagem que envolve “sugerir” o modelo com várias soluções passo a passo para questões existentes antes de apresentá-lo com uma nova questão.

Créditos da imagem: Google
O Minerva ainda comete muitos erros e, às vezes, chega a uma resposta ultimate correta, mas com raciocínio falho. Ainda assim, a equipe espera que sirva de base para modelos que “ajudem a expandir as fronteiras da ciência e da educação”.
A questão do que os sistemas de IA realmente “sabem” é mais filosófica do que técnica, mas como eles organizam esse conhecimento é uma questão justa e relevante. Por exemplo, um sistema de reconhecimento de objetos pode mostrar que “entende” que gatos domésticos e tigres são semelhantes em alguns aspectos, permitindo que os conceitos se sobreponham propositalmente na forma como os identifica – ou talvez não entenda realmente e os dois tipos de criaturas são totalmente alheias a ele.
Pesquisadores da UCLA queriam ver se os modelos de linguagem “compreendiam” as palavras nesse sentido, e desenvolveram um método chamado “projeção semântica” que sugere que sim, eles fazem. Embora você não possa simplesmente pedir ao modelo para explicar como e por que uma baleia é diferente de um peixe, você pode ver como ele associa essas palavras com outras palavras, como mamífero, ampla, balança, e assim por diante. Se a baleia se associa muito a mamíferos e grandes, mas não a escamas, você sabe que ela tem uma ideia decente do que está falando.
Um exemplo de onde os animais se enquadram no espectro pequeno a grande, conforme conceituado pelo modelo.
Como um exemplo simples, eles descobriram que animal coincidia com os conceitos de tamanho, gênero, perigo e umidade (a seleção generation um pouco estranha), enquanto estados coincidiam com clima, riqueza e partidarismo. Os animais são apartidários e os estados são sem gênero, de modo que todas as faixas.
Não há teste mais seguro agora para saber se um modelo entende algumas palavras do que pedir para desenhá-las – e os modelos de texto para imagem estão cada vez melhores. O modelo “Pathways Autoregressive Textual content-to-Symbol” ou Parti do Google parece ser um dos melhores até agora, mas é difícil compará-lo com a concorrência (DALL-E et al.) sem acesso, algo que poucos modelos oferecem . Você pode ler sobre a abordagem Parti aqui, de qualquer forma.
Um aspecto interessante do artigo do Google é mostrar como o modelo funciona com um número crescente de parâmetros. Veja como a imagem melhora gradualmente à medida que os números aumentam:

O advised generation “Uma foto de retrato de um canguru vestindo um capuz laranja e óculos de sol azuis em pé na grama em frente à Sydney Opera Space segurando uma placa no peito que diz Bem-vindos amigos!”
Isso significa que os melhores modelos terão dezenas de bilhões de parâmetros, o que significa que levarão séculos para serem treinados e executados apenas em supercomputadores? Por enquanto, com certeza – é uma abordagem de força bruta para melhorar as coisas, mas o “tique-taque” da IA significa que o próximo passo não é apenas torná-lo maior e melhor, mas torná-lo menor e equivalente. Vamos ver quem consegue fazer isso.
Para não ficar de fora da diversão, Meta também exibiu um modelo de IA generativo esta semana, embora ele afirme que dá mais agência aos artistas que o usam. Tendo brincado muito com esses geradores, parte da diversão é ver o que acontece, mas eles frequentemente apresentam layouts sem sentido ou não “entendem” o advised. O Make-A-Scene da Meta visa corrigir isso.
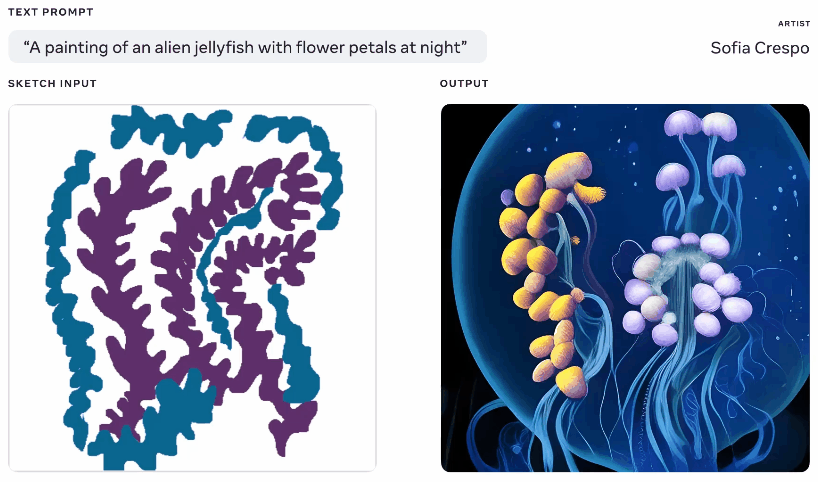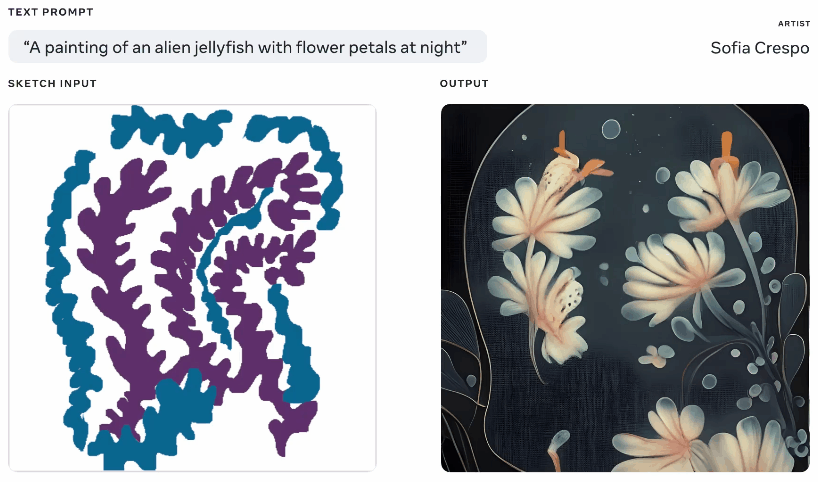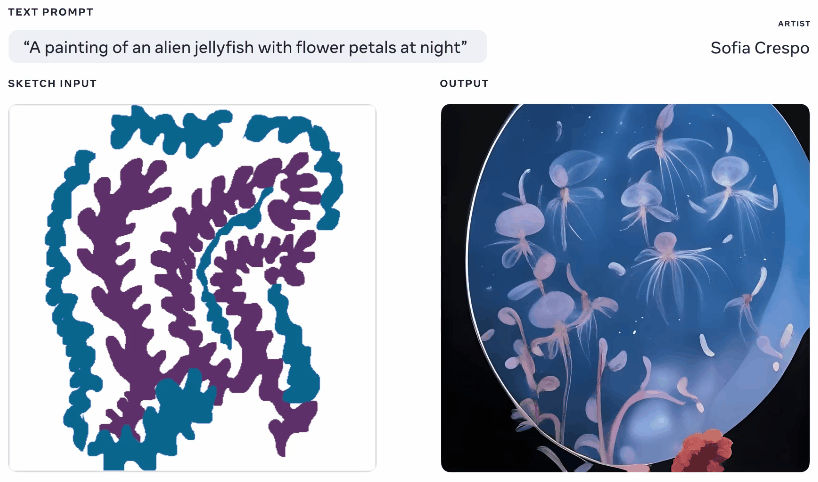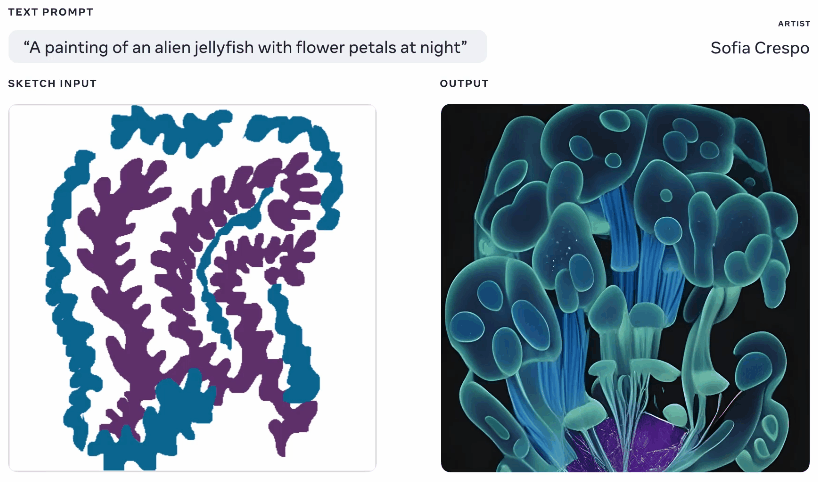
Animação de diferentes imagens geradas a partir do mesmo texto e advised de esboço.
Não é bem uma ideia unique – você pinta uma silhueta básica do que está falando e united states isso como base para gerar uma imagem em cima. Vimos algo assim em 2020 com o gerador de pesadelos do Google. Este é um conceito semelhante, mas ampliado para permitir a criação de imagens realistas a partir de activates de texto usando o esboço como base, mas com muito espaço para interpretação. Pode ser útil para artistas que têm uma ideia geral do que estão pensando, mas desejam incluir a criatividade ilimitada e estranha do modelo.
Como a maioria desses sistemas, o Make-A-Scene não está realmente disponível para uso público, já que, como os outros, é bastante ganancioso em termos de computação. Não se preocupe, em breve teremos versões decentes dessas coisas em casa.
[ad_2]
Fonte da Notícia: techcrunch.com




