[ad_1]
A pesquisa no campo de aprendizado de máquina e IA, agora uma tecnologia-chave em praticamente todos os setores e empresas, é volumosa demais para que qualquer um leia tudo. Esta coluna, Perceptron (anteriormente Ciência Profunda), visa coletar algumas das descobertas e artigos recentes mais relevantes – particularmente, mas não limitado a, inteligência synthetic – e explicar por que eles são importantes.
Esta semana, em IA, uma equipe de engenheiros da Universidade de Glasgow desenvolveu “pele synthetic” que pode aprender a experimentar e reagir à dor simulada. Em outros lugares, pesquisadores da DeepMind desenvolveram um sistema de aprendizado de máquina que prevê onde os jogadores de futebol correrão em um campo, enquanto grupos da Universidade Chinesa de Hong Kong (CUHK) e da Universidade de Tsinghua criaram algoritmos que podem gerar fotos realistas – e até vídeos – de humanos. modelos.
De acordo com um comunicado de imprensa, a equipa de Glasgow pele synthetic alavancou um novo tipo de sistema de processamento baseado em “transistores sinápticos” projetados para imitar os caminhos neurais do cérebro. Os transistores, feitos de nanofios de óxido de zinco impressos na superfície de um plástico flexível, conectados a um sensor de pele que registrava mudanças na resistência elétrica.
Créditos da imagem: Universidade de Glasgow
Embora a pele synthetic tenha sido tentada antes, a equipe afirma que seu design diferia, pois usava um circuito embutido no sistema para atuar como uma “sinapse synthetic” – reduzindo a entrada a um pico de tensão. Isso acelerou o processamento e permitiu que a equipe “ensinasse” à pele como responder à dor simulada, definindo um limiar de tensão de entrada cuja frequência variava de acordo com o nível de pressão aplicado na pele.
A equipe vê a pele sendo usada em robótica, onde poderia, por exemplo, impedir que um braço robótico entre em contato com temperaturas perigosamente altas.
Tangencialmente relacionado à robótica, a DeepMind afirma ter desenvolvido um modelo de IA, Computador gráfico, que pode antecipar para onde os jogadores de futebol se moverão usando gravações de câmera de apenas um subconjunto de jogadores. Mais impressionante, o sistema pode fazer previsões sobre os jogadores além da visão da câmera, permitindo rastrear a posição da maioria – se não de todos – os jogadores em campo com bastante precisão.
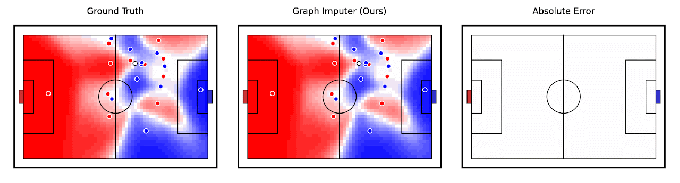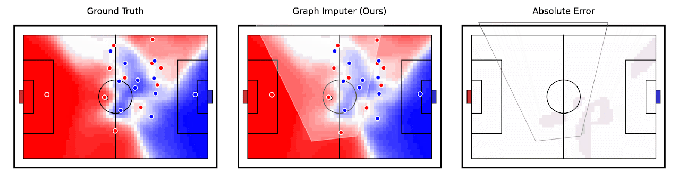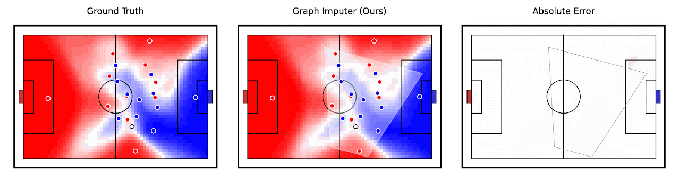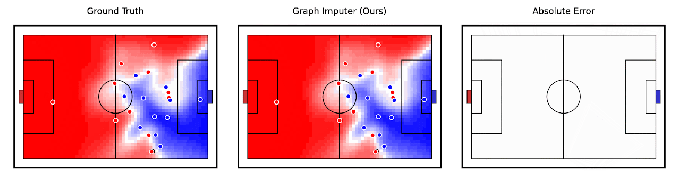
Créditos da imagem: DeepMind
O Graph Imputer não é perfeito. Mas os pesquisadores do DeepMind dizem que ele pode ser usado para aplicações como modelagem de controle de campo ou a probabilidade de um jogador controlar a bola assumindo que ela esteja em um determinado native. (Várias equipes líderes da Premier League usar modelos de controle de campo durante os jogos, bem como na análise pré-jogo e pós-jogo.) Além de futebol e outras análises esportivas, a DeepMind espera que as técnicas por trás do Graph Imputer sejam aplicáveis a domínios como modelagem de pedestres em estradas e modelagem de multidões em estádios.
Embora a pele synthetic e os sistemas de previsão de movimento sejam impressionantes, os sistemas de geração de fotos e vídeos estão progredindo rapidamente. Obviamente, existem trabalhos de alto nível como o do OpenAI Dall-E 2 e do Google Imagem. Mas dê uma olhada Text2Humandesenvolvido pelo CUHK’s Multimedia Lab, que pode traduzir uma legenda como “a senhora veste uma camiseta de manga curta com estampa de cores puras e uma saia curta e denims” em uma foto de uma pessoa que na verdade não existe.
Em parceria com a Academia de Inteligência Synthetic de Pequim, a Universidade de Tsinghua criou um modelo ainda mais ambicioso chamado CogVideo que pode gerar videoclipes a partir de texto (por exemplo, “um homem esquiando”, “um leão está bebendo água”). Os clipes estão repletos de artefatos e outras estranhezas visuais, mas considerando que são cenas completamente fictícias, é difícil criticar também duramente.
O aprendizado de máquina é frequentemente usado na descoberta de medicamentos, onde a variedade quase infinita de moléculas que aparecem na literatura e na teoria precisam ser classificadas e caracterizadas para encontrar efeitos potencialmente benéficos. Mas o quantity de dados é tão grande e o custo de falsos positivos potencialmente tão alto (é caro e demorado buscar leads) que até 99% de precisão não é suficiente. Esse é especialmente o caso de dados moleculares não rotulados, de longe a maior parte do que existe (em comparação com moléculas que foram estudadas manualmente ao longo dos anos).
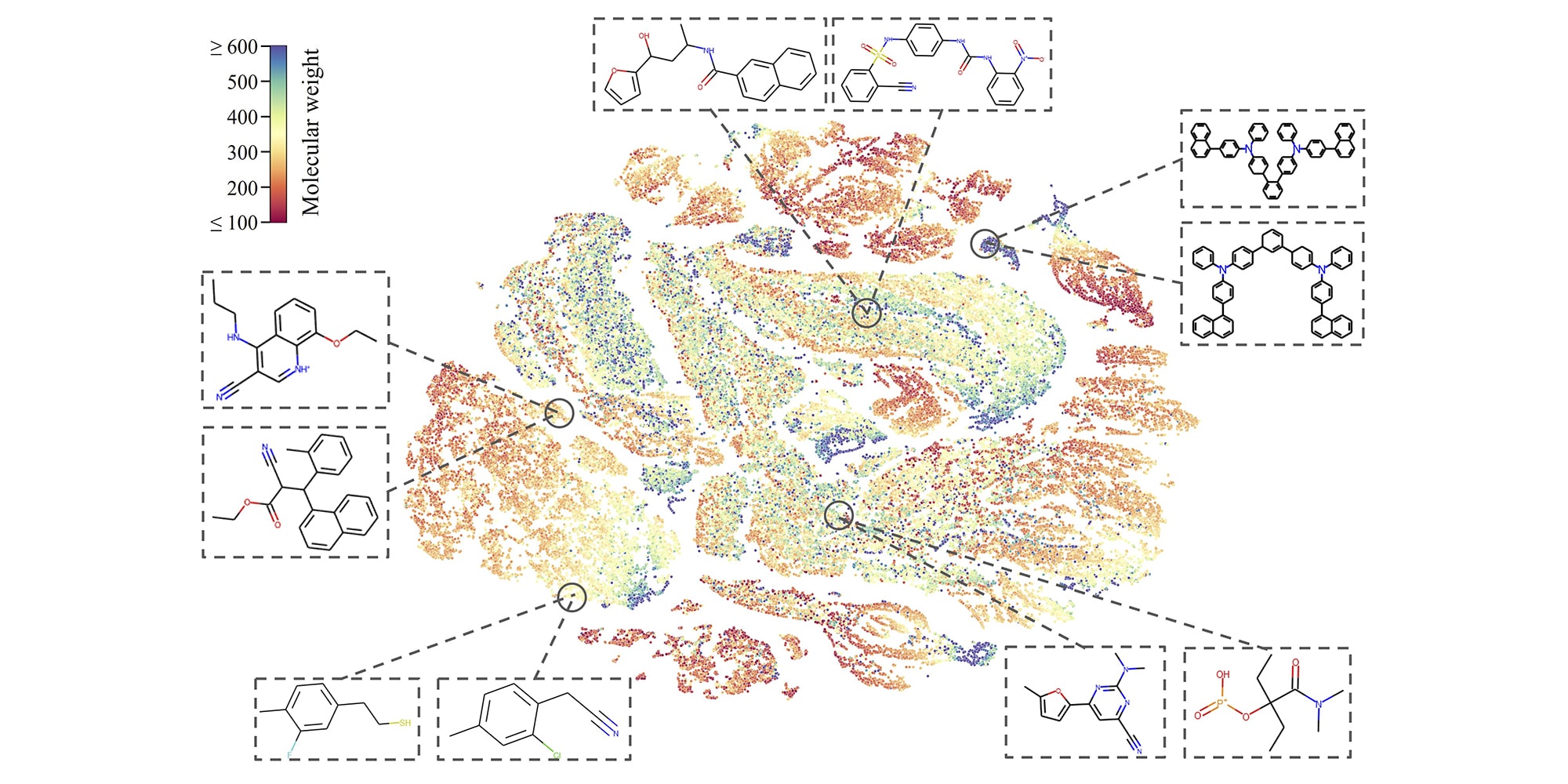
Créditos da imagem: CMU
pesquisadores da CMU estão trabalhando para criar um modelo para classificar bilhões de moléculas não caracterizadas, treinando-as para dar sentido a elas sem nenhuma informação further. Ele faz isso fazendo pequenas alterações na estrutura da molécula (digital), como ocultar um átomo ou remover uma ligação, e observar como a molécula resultante muda. Isso permite que ele aprenda as propriedades intrínsecas de como essas moléculas são formadas e se comportam – e o levou a superar outros modelos de IA na identificação de produtos químicos tóxicos em um banco de dados de teste.
As assinaturas moleculares também são fundamentais no diagnóstico de doenças – dois pacientes podem apresentar sintomas semelhantes, mas uma análise cuidadosa de seus resultados de laboratório mostra que eles têm condições muito diferentes. É claro que essa é a prática médica padrão, mas à medida que os dados de vários testes e análises se acumulam, fica difícil rastrear todas as correlações. A Universidade Técnica de Munique está trabalhando em uma espécie de meta-algoritmo clínico que integra várias fontes de dados (incluindo outros algoritmos) para diferenciar entre certas doenças hepáticas com apresentações semelhantes. Embora esses modelos não substituam os médicos, eles continuarão a ajudar a lidar com os volumes crescentes de dados que até mesmo os especialistas podem não ter pace ou experiência para interpretar.
[ad_2]
Fonte da Notícia



